서버가 두 개 이상일 경우 발생하는 세션 불일치 문제 해결하기
지난번에 포스팅했던 서버를 확장하는 방법에서 scale out 방식으로 서버를 확장했을때 발생하는 문제점 중 하나인 세션 불일치 문제를 해결하기 위한 방법을 알아보자.
세션의 불일치가 무슨뜻일까?
단일 서버 환경에서는 session을 통한 로그인을 구현할때 session 불일치 문제를 신경쓸 필요가 없었다. 하지만 우리가 만든 프로젝트가 유명해져서 한대의 서버로 운영하는것이 불가능해졌다고 가정해보자.
scale-out 방식을 사용해서 서버를 여러대로 늘렸을 때 발생하는 문제점중 하나가 바로 세션 불일치 문제다. 아래 그림들을 통해 무슨뜻인지 이해해보자.

- 먼저 3대의 서버중 서버1에서 로그인을 진행했다. 이 경우, 서버1에서는 해당 클라이언트의 login session이 존재하지만 서버2와 서버3에서는 해당 클라이언트의 login session이 존재하지 않는다.

- 클라이언트가 로그인 한 후 게시판에 글을 쓰기 위해 글쓰기 버튼을 눌렀는데, 로드 밸런서에 의해 해당 글쓰기 작업은 서버2로 요청되었다.
로드밸런싱 : 하나의 인터넷 서비스가 발생하는 트래픽이 많을 때 여러 대의 서버가 분산처리하여 서버의 로드율 증가, 부하량, 속도저하 등을 고려하여 적절히 분산처리하여 해결해주는 서비스입니다.

- 서버2에는 해당 클라이언트의 session이 저장되어있지 않기 때문에 서버2는 로그인 후 이용하라는 응답을 클라이언트에게 보낸다. 사용자 입장에서는 분명 로그인을 했는데 다시 로그인 하라는 요청을 받게되는 것이다.
해결 방법
이러한 세션의 정합성 문제를 해결하기 위한 방법에는 무엇이 있는지 살펴보자.
1. Sticky Session
Sticky란 번역하면 끈적임,껌딱지 라는 뜻이다. 처음 작업이 요청에 대한 응답을 준 서버에서 해당 클라이언트의 작업을 담당하는 것이다. 쉽게 말해서 해당 서버에 껌딱지처럼 붙어있다고 생각하면 된다.

위 그림처럼 클라이언트가 서버1에서 로그인 작업을 통해 세션을 생성했다면 해당 클라이언트 에 대한 앞으로의 모든 요청도 서버1이 담당하게 되는 것이다. 항상 동일한 서버에 요청을 하는것이 아닌 클라이언트의 요청에 쿠키가 존재하는지 확인 후 요청 작업이 이루어진다.
만약 쿠키가 존재하지 않는다면 기존 로드밸런싱 방법에 의해 요청이 이루어진다.
하지만 이 방법에는 치명적인 단점이 존재한다.
- 특정 서버에 트래픽이 집중되는 문제가 발생할 수 있다.
여러 사용자들이 로그인을 하게 되면 서버에 세션이 저장되고, 이 과정에서 로드 밸런서는 서버 간 균형을 맞춰 적절하게 분배했을 것이다. 하지만 이후 사용자들의 활동에서는 큰 차이를 보일 수 있다. 어떤 사용자는 로그인만 해놓고다른 일을처리할 수도있고, 어떤 사용자는 해당 서비스를 적극적으로 이용할 수도 있다. 이렇게 되면 적극적으로 서비스를 이용하는 사용자의 세션이 저장된 서버에만 트래픽이 몰리기 때문에 특정 서버에 트래픽이 집중되는 문제가 발생하는 것이다. 이렇게 되면 애초에Scale-out방식으로 서버를 확장한 의미가 조금은 퇴색되는 듯 보인다.
- 세션 정보가 유실될 수 있다.
만약 사용자의 세션 정보가 저장된 서버가 다운된다면, 로드 밸런서는 다운된 서버를 제외한 나머지 서버에 요청을 하게 될 것이다. 이렇게 해당 서버는 해당 사용자의 로그인 정보를 가지고 있지 않기 때문에 다시 한번 세션 불일치 문제가 발생할 수 있다.
2. WAS에서 지원하는 Session Clustering
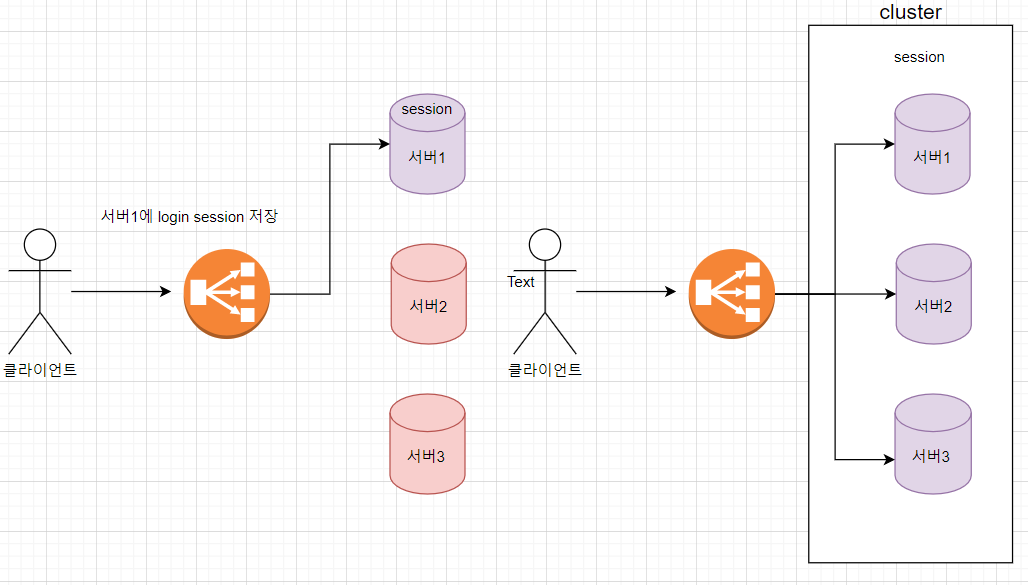
WAS마다 session clustering을 지원하는 방식이 조금씩 다른데, 그중 가장 대표적 WAS인 톰캣이 지원하는 방식은 all-to-all 방식으로 해당 서버에 저장된 session의 정보를 다른 서버에 전파하는 방식을 취하고 있다.
예를들어 서버1에서 login session이 저장되었다면, 서버2와 서버3에도 서버1에 저장되어있는 세션을 전파(복사)하는 것이다. 따라서 1번 방법의 문제점인 특정 서버에만 트래픽이 몰리는 문제를 해결할 수 있게 되었다.
하지만 이 방법은 소규모 클러스터에는 적합하지만 4대 이상의 대규모 클러스터에는 적합한 방식이 아니다.
1. 세션을 전파(복사)하는 작업을 진행하기 때문에 모든 서버에 동일한 세션 정보다 저장된다. 즉, 효율적인 메모리 관리가 이루어지지 않는다.
2. 데이터 변경이 발생할때 마다 세션을 전파(복사)하는 작업이 일어나기 때문에 네트워크 트래픽이 증가하게 된다.
3. 세션 전파 작업 중 모든 서버에 세션이 전파되기까지의 시간차로 인한 세션 불일치 문제와 같은 예상치 못한 문제가 발생할 가능성이 존재한다.
따라서 이 방법은 비교적 적은 서버의 개수 (4개 이하)를 가질 때 유용하다.(세션 불일치 가능성이 적고, 네트워크 트래픽이 발생해도 소량의 서버에서는 성능상 크게 문제가 되지 않기 때문에)
3. 별도의 세션 저장소를 두는 방법
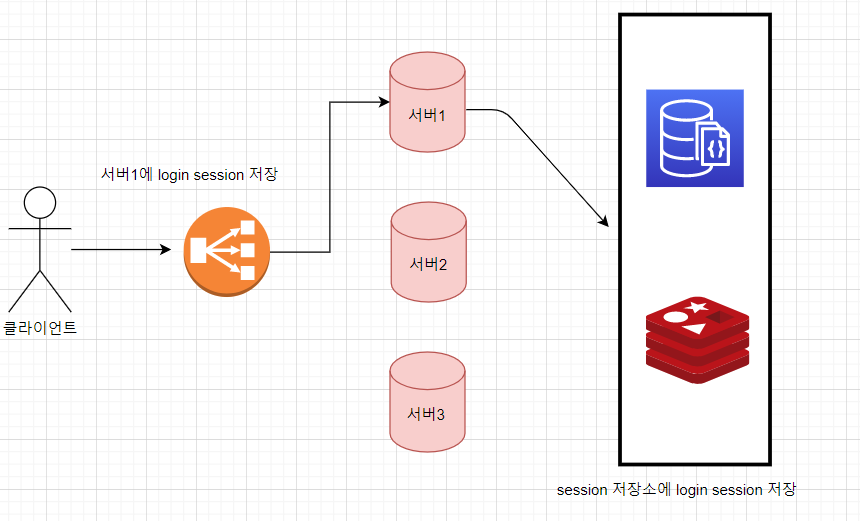
마지막으로 독립된 세션 스토리지로 세션을 관리하는 방법이다.
각 서버와 연결된 독립된 세션 저장소(서버)를 구성하여 로그인이 요청된 서버에 세션 정보를 저장하는 것이 아닌 앞서 언급한 독립된 세션 저장소(서버)에 세션 정보를 저장하고 여러 서버들이 독립된 세션 저장소에서 세션 정보를 읽어오는 방식이다.
해당 방법을 사용하면 Sticky session의 문제점인 특정 서버로 트래픽이 몰리는 문제가 발생하지 않고, 또한 세션이 재설정되어도 모든 서버들이 수정되는 것이 아닌, 세션 저장소에 있는 세션 정보만 수정하면 되기 때문에 WAS들끼리 불필요한 네트워크 통신 과정을 진행하지 않아도 된다는 장점이 있다.
하지만 이 방법에도 단점은 존재한다. 만약 독립된 세션 저장소에 문제가 생긴다면 모든 WAS의 서비스에도 영향을 끼친다는 것이다. 이러한 문제를 보완하기 위해 동일한 세션 저장소를 하나 더 구성하는 방법(마스터-슬레이브 복제)으로 해당 문제를 해결하곤 한다.
저장소로는 MySQL, OracleDB 등 RDBMS 사용할 수도 있고 Redis와 Memcached 같은 In memory DB를 사용할 수 도 있다. 해당 방법으로 세션의 정합성 문제를 해결할때 세션 저장소로 어떤것을 사용할지 고민해보고, 그에 따른 타당한 이유가 뒷받침 되어야 한다.
'프로젝트 : shoe-auction' 카테고리의 다른 글
| [Spring] Cache를 적용하여 응답속도 개선하기 (0) | 2021.03.06 |
|---|---|
| [Spring] 프로젝트에 Spring Rest Docs 적용하기 (0) | 2021.03.02 |
| [Spring] 권한 설정을 통한 특정 리소스 접근 제한하기 (0) | 2021.02.17 |
| [Spring] 커스텀 어노테이션으로 로그인 확인과 현재 로그인된 사용자 정보 불러오기 (0) | 2021.02.06 |
| Session storage로 적합한 데이터 베이스는 무엇일까? (Redis vs Memcached) (3) | 2021.01.27 |
